library(lmtest)Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
해당 자료는 전북대학교 이영미 교수님 2023응용통계학 자료임
library(lmtest)Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
dt <- data.frame(x = c(15,26,10,9,15,20,18,11,
8,20,7,9,10,11,11,10,12,42,17,11,10),
y = c(95,71,83,91,102,87,93,100,
104,94,113,96,83,84,102,100,
105,57,121,86,100))######## 산점도
plot(y~x, dt,pch = 20,cex = 2,col = "darkorange")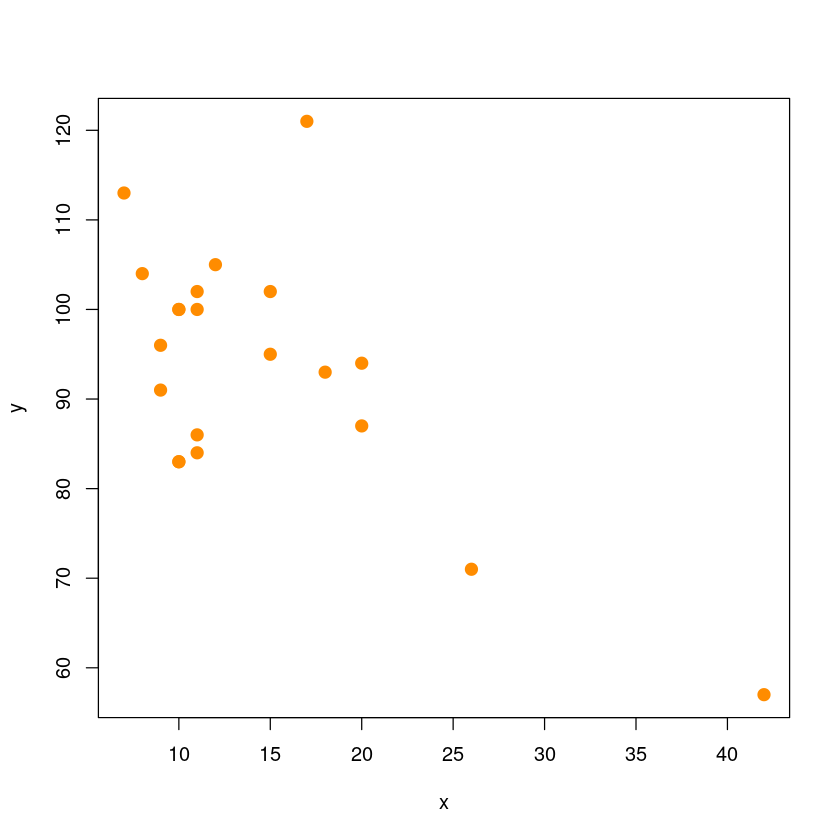
######## 회귀적합
model_reg <- lm(y~x, dt)
summary(model_reg)
Call:
lm(formula = y ~ x, data = dt)
Residuals:
Min 1Q Median 3Q Max
-15.604 -8.731 1.396 4.523 30.285
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 109.8738 5.0678 21.681 7.31e-15 ***
x -1.1270 0.3102 -3.633 0.00177 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 11.02 on 19 degrees of freedom
Multiple R-squared: 0.41, Adjusted R-squared: 0.3789
F-statistic: 13.2 on 1 and 19 DF, p-value: 0.001769plot(y~x, dt,pch = 20,cex = 2,col = "darkorange")
abline(model_reg, col='steelblue', lwd=2)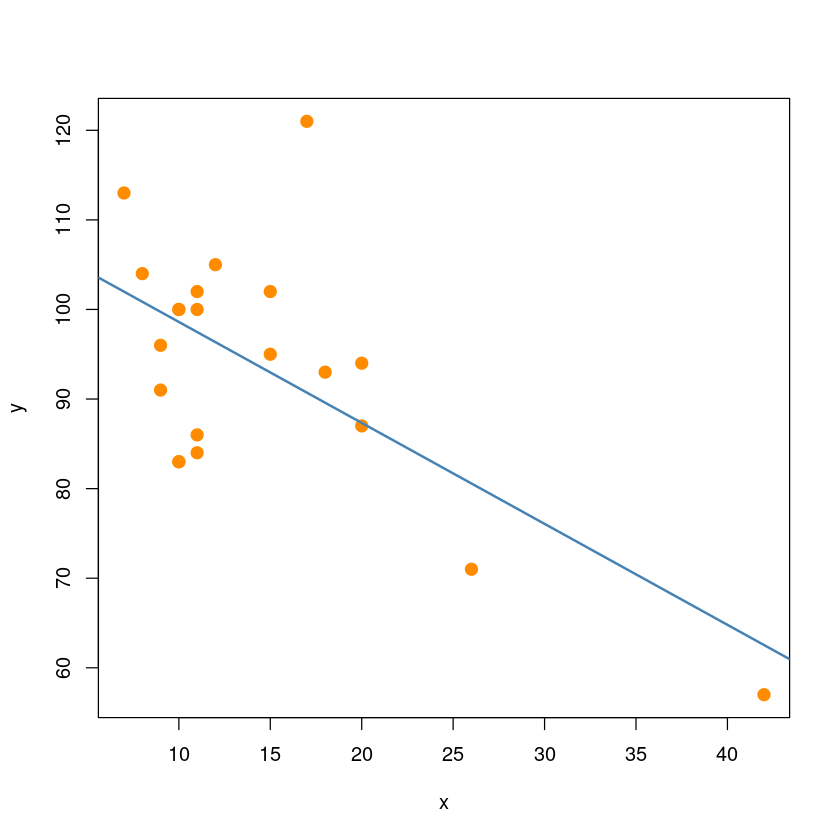
X = cbind(rep(1, nrow(dt)), dt$x)
H = X %*% solve(t(X) %*% X) %*% t(X)
diag(H)21x21행렬
0.0628157755825353 18번쨰가 큰값을 가지고 있음. leverage일 확률이 크다.
sum(diag(H))hatvalues(model_reg)hatvalues는 \(h_{ii}\)값 바로 나오게 하는 함수
which.max(hatvalues(model_reg)) # 가장 큰 값의 번호
hatvalues(model_reg)[which.max(hatvalues(model_reg))] ##h_{18,18}값2*(1+1)/nrow(dt)\(h_{18,18} > 2 \bar h=2 \dfrac{p+1}{n}=2\dfrac{2}{21}=0.19047619047619\)이므로 18번째 관측값이 leverage point 로 고려 가능
hatvalues(model_reg)>0.190476190476190.19047619047619보다 큰값이 있다면 leverage point
plot(y~x, dt,pch = 20,cex = 2,col = "darkorange")
text(dt[18,],"18", pos=2)
abline(model_reg, col='steelblue', lwd=2)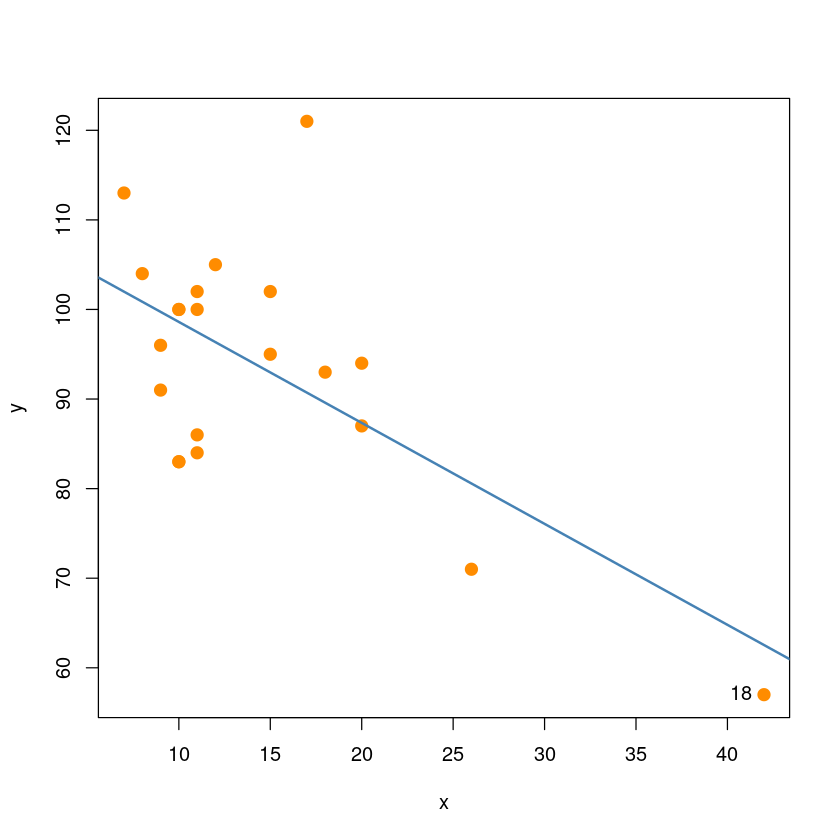
residual <- model_reg$residuals
head(residual)hist(residual)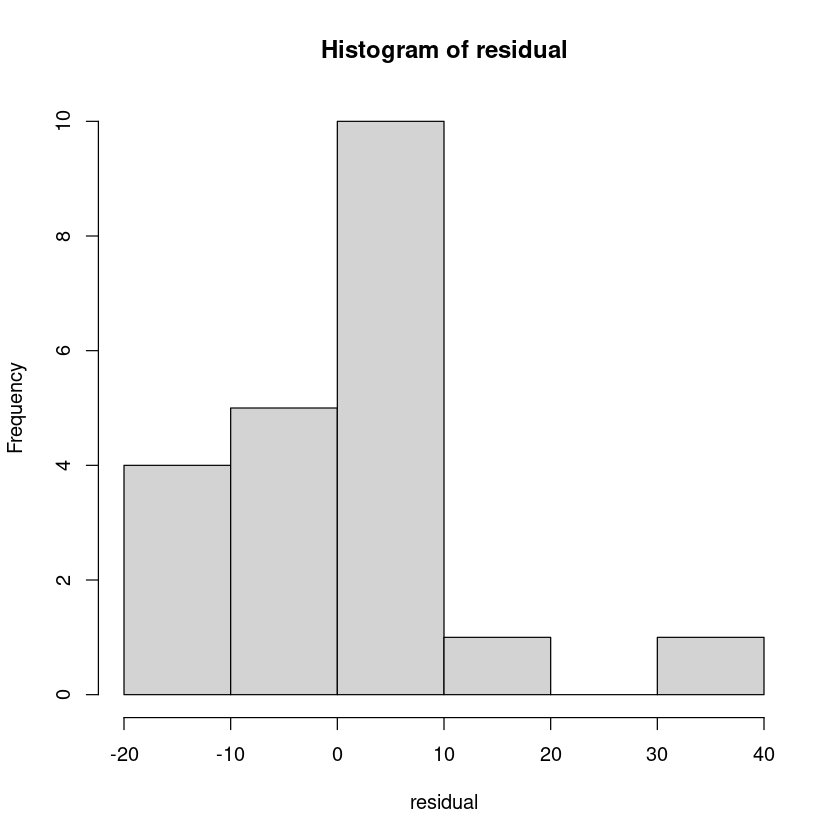
아마도\(N(0,1)\)을 따를거야. 하지만 \(\hat \sigma\)이므로 완벽한 정규분포는 아니고 그렇다면 t분포냐? 독립이 아니므로 t분포가 아니다. N이 충분히 크다면 대략적으로 정규분포를 따른다고 볼 수 있다.
\(e_i\) ~ \(N(0,\sigma^2(1-h_{ii}))\)
s_residual <- rstandard(model_reg)
head(s_residual)# 또는
s_xx <- sum((dt$x-mean(dt$x))^2) #S_xx
h_ii <- 1/21 + (dt$x- mean(dt$x))^2/s_xx #hatvalues로 구해도 됨. 혹은 X(X^TX)-1X^T로 해도 됨
### h_ii <- hatvalues(model_reg)
### h_ii <- influence(model_reg)$hat
hat_sigma <- summary(model_reg)$sigma #hat sigma
s_residual <- resid(model_reg)/(hat_sigma*sqrt(1-h_ii)) ## 내적hist(s_residual)
\(t(n-p-2)=(n-1-p-1)\)
\(\hat \sigma_i : i\)번째 측정값 \(y_i\)를 제외하고 얻어진 \(\hat \sigma\)
\(\hat \sigma_i^2 = \left[ (n-p-1) \hat \sigma^2 - \dfrac{e_i^2}{1-h_{ii}} \right] / (n-p-2)\)
\(|r_i^*| \geq t_{\alpha/2}(n-p-2)\)이면 이상치
s_residual_i <- rstudent(model_reg)
head(s_residual_i)# 또는
hat_sigma_i <- sqrt(((21-1-1)*hat_sigma^2 - residual^2/(1-h_ii) )/(21-1-2))
## hat_sigma_i <- influence(model_reg)$sigma
s_residual_i <- residual/(hat_sigma_i*sqrt(1-h_ii)) ## 외적hist(s_residual_i)
which.max(s_residual_i)
s_residual_i[which.max(s_residual_i)]qt(0.975, 21-1-2)\(t_{0.025}(21-1-1) : \alpha=5\%\)
\(|r_i^*| \geq t_{\alpha/2}(n-p-2)\)이면, 유의수준 \(\alpha\)에서, \(i\)번째 관측값이 이상점이라고 할 수 있다.
따라서 19번째 관측값은 유의수준 0.05에서 이상점이라고 할 수 있다.
plot(y~x, dt,pch = 20,cex = 2,col = "darkorange")
text(dt[19,],"19", pos=2)
abline(model_reg, col='steelblue', lwd=2)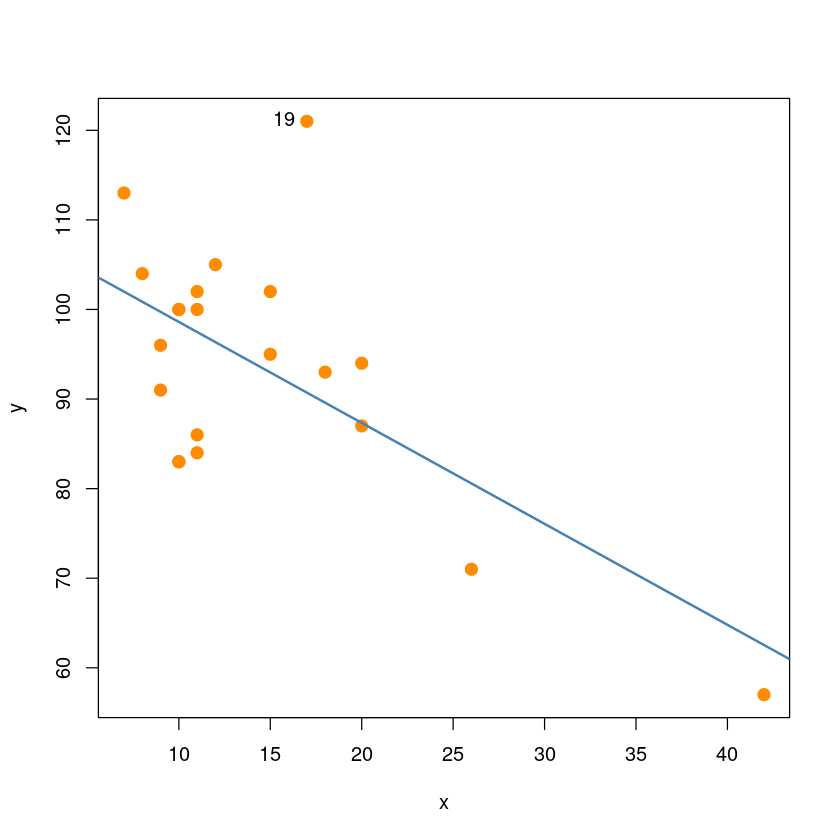
s_residual_i[which(abs(s_residual_i)>qt(0.975,21-2))]## 잔차그림
par(mfrow = c(2, 2))
plot(fitted(model_reg), residual,
pch=20,cex = 2,col = "darkorange",
xlab = "Fitted", ylab = "Residuals",
main = "residual plot")
abline(h=0, lty=2)
plot(fitted(model_reg), s_residual,
pch=20,cex = 2,col = "darkorange",
xlab = "Fitted", ylab = "S_Residuals",
ylim=c(min(-3, min(s_residual)),
max(3,max(s_residual))),
main = "standardized residual plot")
abline(h=c(-2,0,2), lty=2)
plot(fitted(model_reg), s_residual_i,
pch=20,cex = 2,col = "darkorange",
xlab = "Fitted", ylab = "S_Residuals_(i)",
ylim=c(min(-3, min(s_residual_i)),
max(3,max(s_residual_i))),
main = "studentized residual plot")
abline(h=c(-3,-2,0,2,3), lty=2)
plot(fitted(model_reg), s_residual_i,
pch=20,cex = 2,col = "darkorange",
xlab = "Fitted", ylab = "S_Residuals_(i)",
ylim=c(min(-3, min(s_residual_i)),
max(3,max(s_residual_i))),
main = "studentized residual plot")
abline(h=c(-qt(0.975,21-2),0,qt(0.975,21-2)), lty=2)
text (fitted(model_reg)[which(abs(s_residual_i)>qt(0.975,21-2))],
s_residual_i[which(abs(s_residual_i)>qt(0.975,21-2))],
which(abs(s_residual_i)>qt(0.975,21-2)),adj = c(0,1))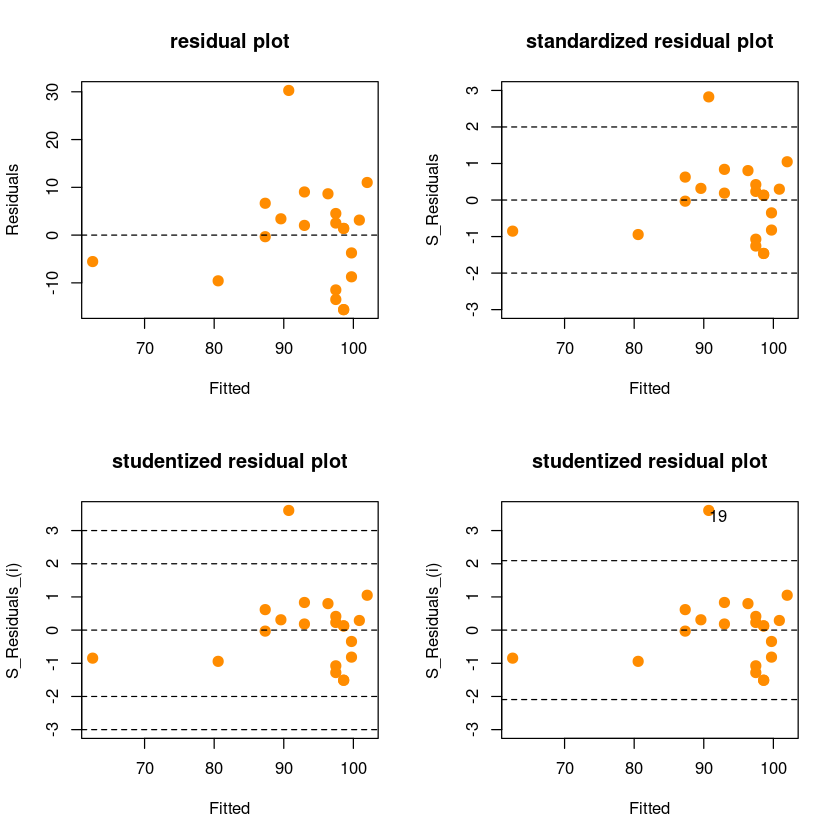
## 정규성 검정
par(mfrow=c(1,2))
hist(resid(model_reg),
xlab = "Residuals",
main = "Histogram of Residuals",
col = "darkorange",
border = "dodgerblue",
breaks = 20)
qqnorm(resid(model_reg),
main = "Normal Q-Q Plot",
col = "darkgrey",
pch=16)
qqline(resid(model_reg), col = "dodgerblue", lwd = 2)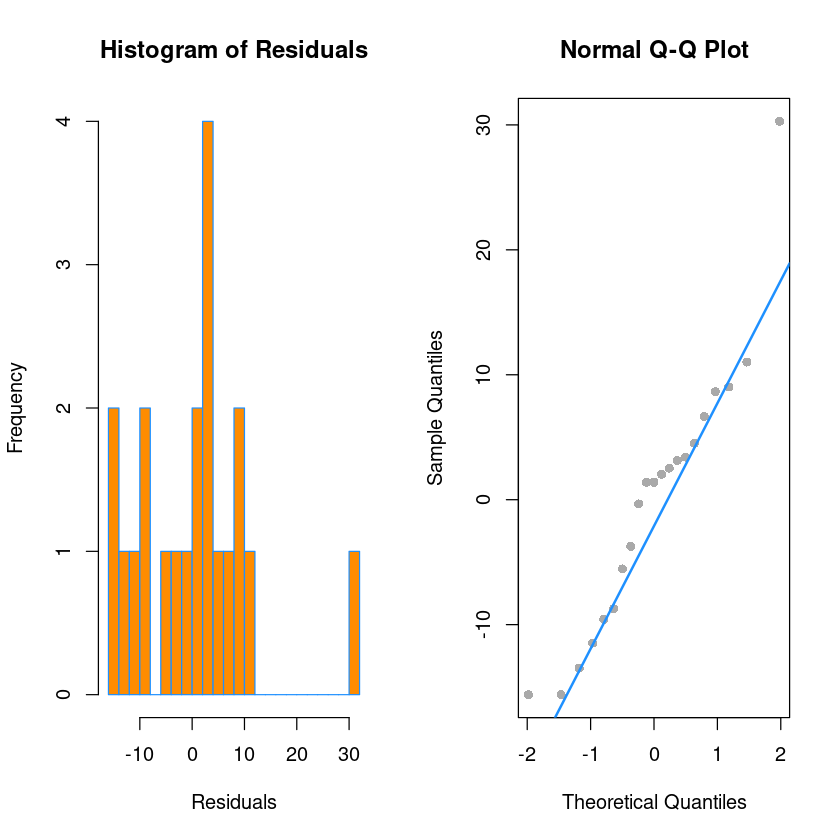
## Shapiro-Wilk Test
## H0 : normal distribution vs. H1 : not H0
shapiro.test(resid(model_reg))
Shapiro-Wilk normality test
data: resid(model_reg)
W = 0.92578, p-value = 0.1133## 독립성 검정
lmtest::dwtest(model_reg)
Durbin-Watson test
data: model_reg
DW = 2.0844, p-value = 0.5716
alternative hypothesis: true autocorrelation is greater than 0### 등분산성
## H0 : 등분산 vs. H1 : 이분산 (Heteroscedasticity)
bptest(model_reg)
studentized Breusch-Pagan test
data: model_reg
BP = 0.0014282, df = 1, p-value = 0.9699plot(y~x, dt,pch = 20,cex = 2,col = "darkorange")
abline(model_reg, col='steelblue', lwd=2)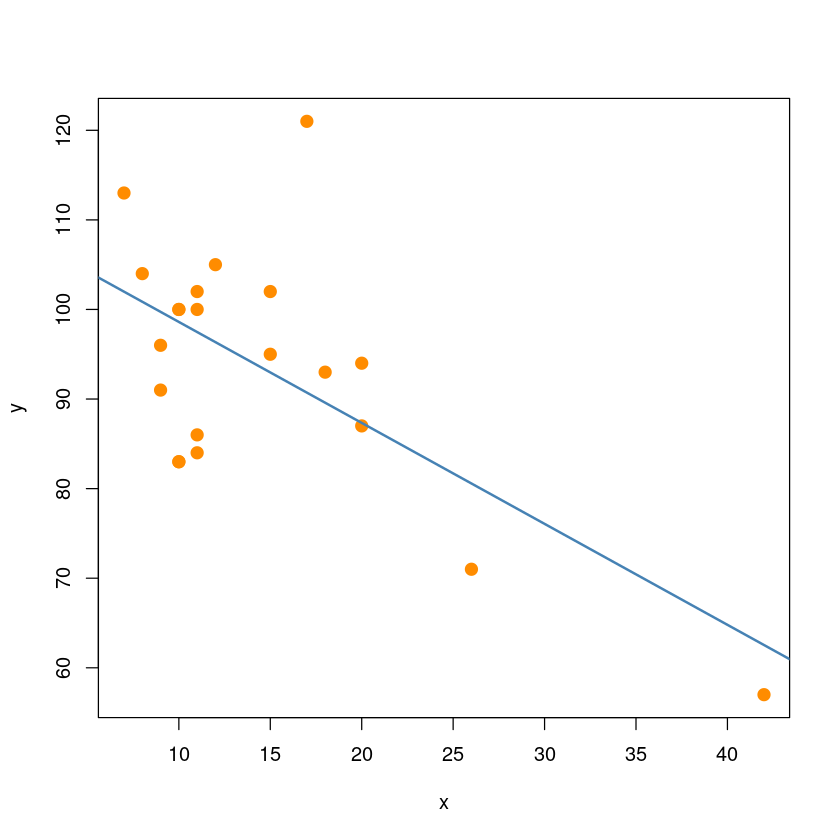
influence(model_reg)| (Intercept) | x | |
|---|---|---|
| 1 | 0.086545033 | 0.001045618 |
| 2 | 0.958749611 | -0.104156236 |
| 3 | -1.623423657 | 0.057755211 |
| 4 | -1.022877601 | 0.040022565 |
| 5 | 0.384830249 | 0.004649436 |
| 6 | 0.005894578 | -0.001602673 |
| 7 | 0.023216186 | 0.010379001 |
| 8 | 0.230329653 | -0.007159985 |
| 9 | 0.410719785 | -0.017252806 |
| 10 | -0.117621441 | 0.031980023 |
| 11 | 1.595051450 | -0.070799821 |
| 12 | -0.437100147 | 0.017102603 |
| 13 | -1.623423657 | 0.057755211 |
| 14 | -1.230320253 | 0.038245507 |
| 15 | 0.412910892 | -0.012835671 |
| 16 | 0.145243868 | -0.005167222 |
| 17 | 0.681955144 | -0.017203712 |
| 18 | 4.243970455 | -0.347768136 |
| 19 | 0.569162106 | 0.066321856 |
| 20 | -1.047739014 | 0.032569820 |
| 21 | 0.145243868 | -0.005167222 |
coefficients:(Intercept)=\(\beta_0\),x=\(\beta_1\)
0.001045618= \(\hat \beta_1 - \tilde \beta_1\) : (포함하여)21개로 돌린거랑 (1번째 변수빼고)20개로 돌린거의 차이값
-0.005167222= \(\hat \beta_1 - \tilde \beta_1\) : (포함하여)21개로 돌린거랑 (21번째 변수빼고)20개로 돌린거의 차이값값이 크면 영향점으로 생각
18번째 데이터가 살짝 커보인다.
$sigma: \(\hat \sigma_{(i)}\)
$wt.res: 신경쓰지말자
influence.measures(model_reg)Influence measures of
lm(formula = y ~ x, data = dt) :
dfb.1_ dfb.x dffit cov.r cook.d hat inf
1 0.01664 0.00328 0.04127 1.166 8.97e-04 0.0479
2 0.18862 -0.33480 -0.40252 1.197 8.15e-02 0.1545
3 -0.33098 0.19239 -0.39114 0.936 7.17e-02 0.0628
4 -0.20004 0.12788 -0.22433 1.115 2.56e-02 0.0705
5 0.07532 0.01487 0.18686 1.085 1.77e-02 0.0479
6 0.00113 -0.00503 -0.00857 1.201 3.88e-05 0.0726
7 0.00447 0.03266 0.07722 1.170 3.13e-03 0.0580
8 0.04430 -0.02250 0.05630 1.174 1.67e-03 0.0567
9 0.07907 -0.05427 0.08541 1.200 3.83e-03 0.0799
10 -0.02283 0.10141 0.17284 1.152 1.54e-02 0.0726
11 0.31560 -0.22889 0.33200 1.088 5.48e-02 0.0908
12 -0.08422 0.05384 -0.09445 1.183 4.68e-03 0.0705
13 -0.33098 0.19239 -0.39114 0.936 7.17e-02 0.0628
14 -0.24681 0.12536 -0.31367 0.992 4.76e-02 0.0567
15 0.07968 -0.04047 0.10126 1.159 5.36e-03 0.0567
16 0.02791 -0.01622 0.03298 1.187 5.74e-04 0.0628
17 0.13328 -0.05493 0.18717 1.096 1.79e-02 0.0521
18 0.83112 -1.11275 -1.15578 2.959 6.78e-01 0.6516 *
19 0.14348 0.27317 0.85374 0.396 2.23e-01 0.0531 *
20 -0.20761 0.10544 -0.26385 1.043 3.45e-02 0.0567
21 0.02791 -0.01622 0.03298 1.187 5.74e-04 0.0628 dfb.1_ , dfb.x : \((\hat \beta_1 - \tilde \beta_{1(i)})/\)뭘로나누자
inf : 영향점인 것 같으면 *로 표시
DFFITS: \(DFFITS(i) = \dfrac{\hat y_i - \tilde y_i(i)}{\hat \sigma_{(i)} \sqrt{h_{ii}}}\)
\(|DFFITS(i)| \geq 2 \sqrt{\dfrac{p+1}{n-p-1}}\)이면 영향점
dffits(model_reg) which(abs(dffits(model_reg)) > 2*sqrt(2/(21-2)))Cook’s Distance
\(D(i) = \dfrac{\sum_{i=1}^n (\hat y_j - \hat y_j(i))^2}{(p+1)\hat \sigma^2}=\dfrac{(\hat \beta - \hat \beta(i))^T X^T X (\hat \beta - \hat \beta(i))}{(p+1) \hat \sigma^2}\)
\(\hat \beta(i): i\)번째 관측치를 제외하고 \(n-1\)개의 관측값에서 구한 \(\hat \beta\)의 최소제곱추저량
cooks.distance(model_reg)qf(0.5,2,21-2)which(cooks.distance(model_reg) >qf(0.5,2,21-2))없다!
\(COVRATIO(i) = \dfrac{1}{\left[1+\dfrac{(r_i^*)^2-1}{n-p-1}\right]^{p+1}(1-h_{ii})}\)
\(|COVRATIO(i)-1| \geq 3(p+1)/n\)이면 \(i\)번째 관측치를 영향을 크게 주는 측정값으로 볼 수 있음
covratio(model_reg)which(abs(covratio(model_reg)-1) > 3*(1+1)/21)summary(influence.measures(model_reg))Potentially influential observations of
lm(formula = y ~ x, data = dt) :
dfb.1_ dfb.x dffit cov.r cook.d hat
18 0.83 -1.11_* -1.16_* 2.96_* 0.68 0.65_*
19 0.14 0.27 0.85 0.40_* 0.22 0.05 ## 18제거 전후
plot(y~x, dt,pch = 20,
cex = 2,col = "darkorange",
main = "18번 제거")
abline(model_reg, col='steelblue', lwd=2)
abline(lm(y~x, dt[-18,]), col='red', lwd=2)
text(dt[18,], pos=2, "18")
legend('topright', legend=c("full", "del(18)"),
col=c('steelblue', 'red'), lty=1, lwd=2)
# high leverage and high influence, not outlier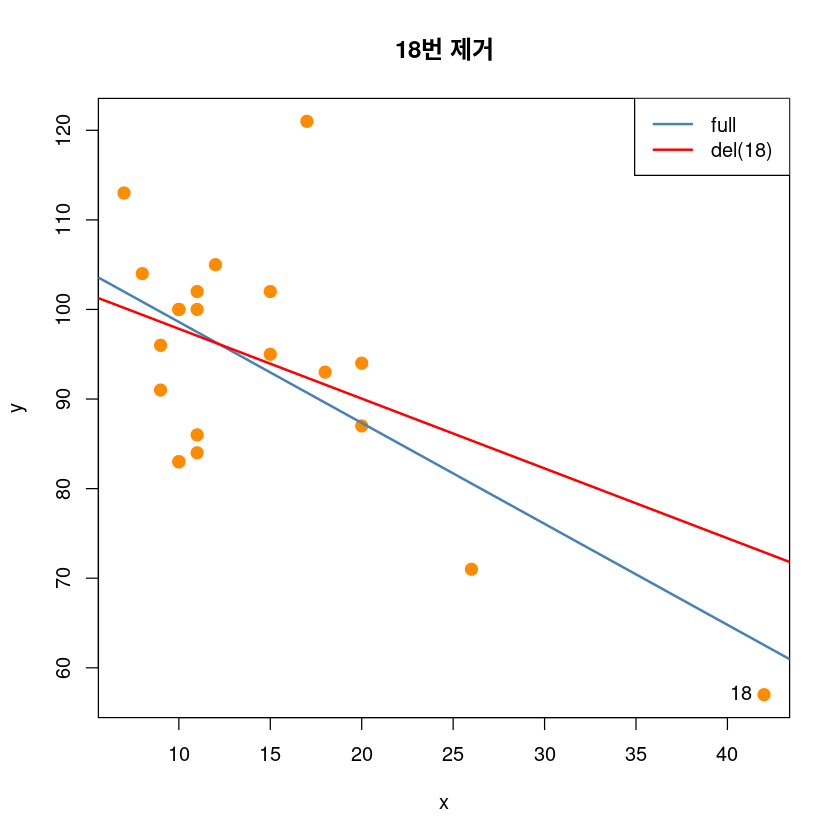
## 19제거 전후
plot(y~x, dt,pch = 20,
cex = 2,col = "darkorange",
main = "19번 제거")
abline(model_reg, col='steelblue', lwd=2)
abline(lm(y~x, dt[-19,]), col='red', lwd=2)
text(dt[19,], pos=2, "19")
legend('topright', legend=c("full", "del(19)"),
col=c('steelblue', 'red'), lty=1, lwd=2)
# not leverage and high influence, outlier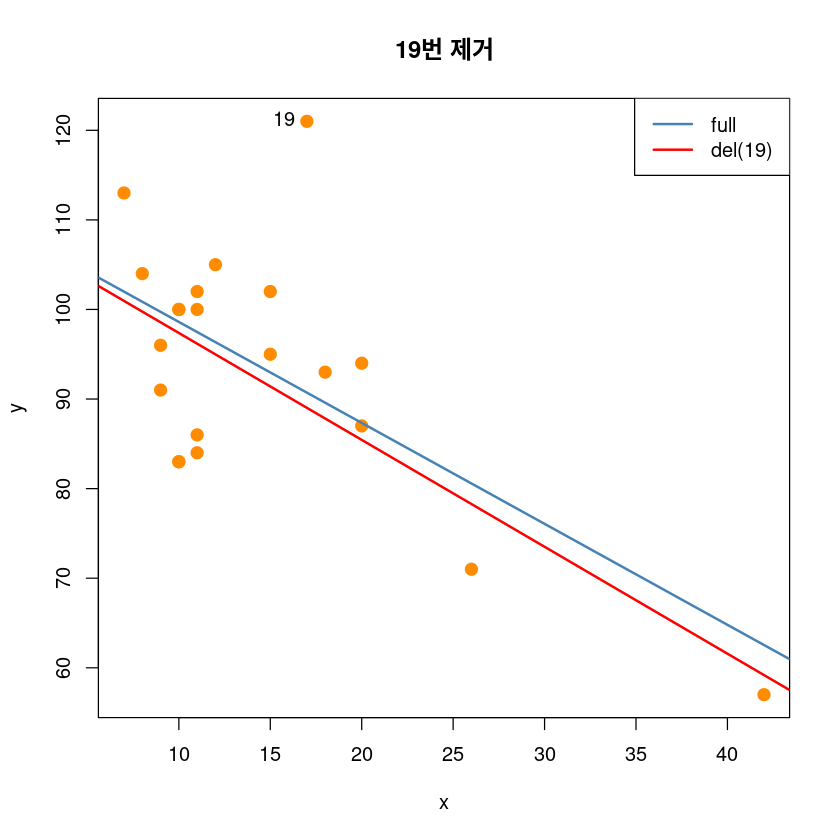
## 18, 19제거 전후
plot(y~x, dt,pch = 20,
cex = 2,col = "darkorange",
main = "18,19번 제거")
abline(model_reg, col='steelblue', lwd=2)
abline(lm(y~x, dt[-c(18,19),]), col='red', lwd=2)
text(dt[c(18,19),], pos=2, c("18","19"))
legend('topright', legend=c("full", "del(18,19)"),
col=c('steelblue', 'red'), lty=1, lwd=2)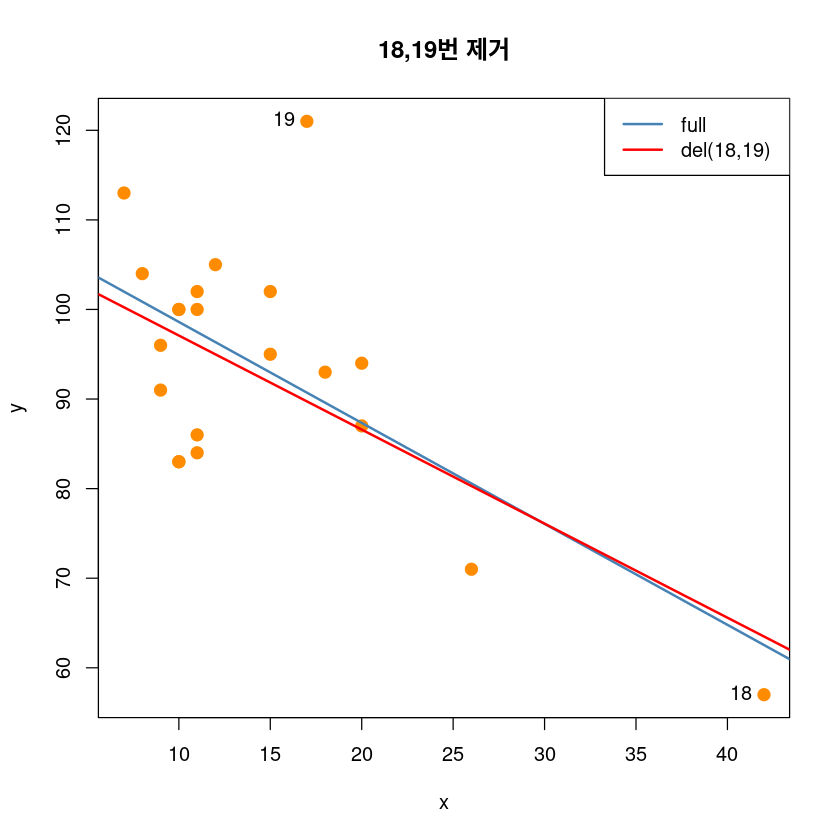
## 회귀진단 그림
par(mfrow = c(2, 2))
plot(model_reg, pch=16)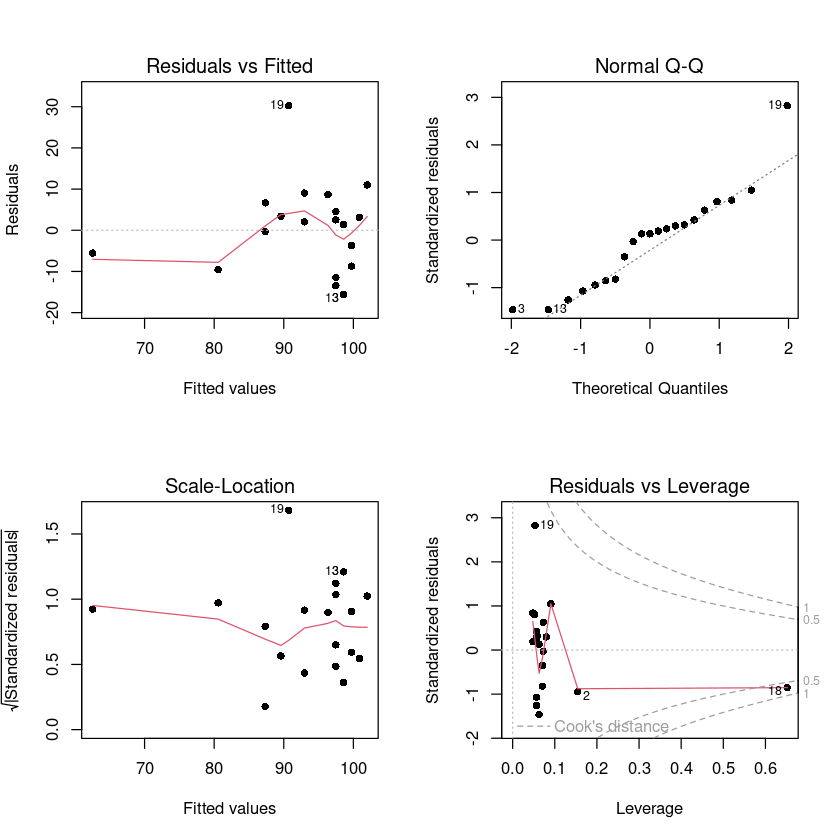
왼쪽위에: \(e_i, \hat y_i\)그림
왼쪽아래: \(\sqrt{|r_i|}\)
오른쪽 아래: 이상치, 영향점, leverage다볼수잇당